
Understanding 1717940029566.sst Files
Files with names like 1717940029566.sst are integral components of databases utilizing LevelDB or its derivatives, such as RocksDB. These files, known as Sorted String Table (SST) files, are designed to store key-value pairs in a sorted and immutable format, optimizing data retrieval and ensuring efficient storage management. The numerical prefix, such as 1717940029566, serves as a unique identifier, often linked to a sequence number or timestamp, distinguishing each SST file within the database system.
The Role of SST Files in LevelDB
In LevelDB, SST files are fundamental to the database’s architecture. They are created during the flushing process when the in-memory data structure, known as the MemTable, reaches its capacity. This process involves writing the sorted key-value pairs from the MemTable to disk as an SST file, thereby maintaining the database’s performance and ensuring data persistence. The immutability of SST files means that once they are written, they are not modified; instead, any updates result in new SST files, which helps in reducing data corruption risks and maintaining data integrity.
Structure of SST Files
An SST file comprises several components, each serving a specific purpose to facilitate efficient data storage and retrieval:
-
Data Blocks: These contain the actual key-value pairs, stored in a sorted order to allow for quick binary searches during data retrieval operations.
-
Index Block: This block holds pointers to the data blocks, enabling the database to locate specific key-value pairs without scanning the entire file.
-
Filter Block (Optional): Often implemented as a Bloom filter, this block provides a fast, probabilistic method to test whether a key is present in the SST file, reducing unnecessary disk reads.
-
Metaindex Block: This contains metadata about the SST file, including information about the filter block and other properties, aiding in the efficient management of the file.
-
Footer: Located at the end of the file, the footer stores fixed-size metadata that points to the locations of the metaindex and index blocks, serving as a roadmap for reading the file’s contents.
Naming Conventions and Their Significance
The naming convention of SST files, such as 1717940029566.sst, is not arbitrary. The numerical prefix serves as a unique identifier, often corresponding to a sequence number or a timestamp generated by the database engine. This systematic naming helps in organizing and managing multiple SST files, ensuring that each file can be uniquely identified and accessed without ambiguity. The .sst extension denotes that the file is a Sorted String Table file, distinguishing it from other file types within the database system.
Creation and Management of SST Files
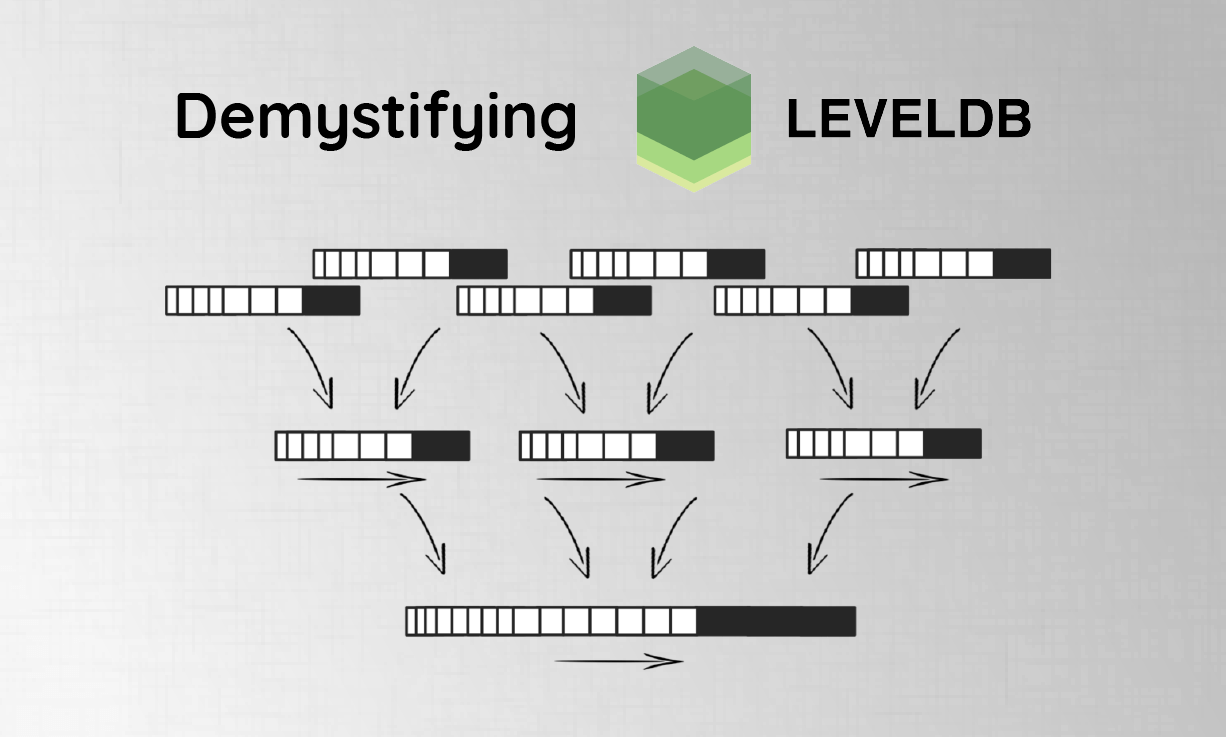
The lifecycle of an SST file begins when data is written to the MemTable. As the MemTable accumulates data, it eventually reaches a predefined threshold, triggering a flush operation. During this operation, the contents of the MemTable are written to disk as a new SST file. Over time, as more SST files are created, the database performs a process called compaction. Compaction involves merging multiple SST files to eliminate redundant data, reduce storage space, and improve read performance by minimizing the number of files that need to be searched during a query.
Compaction: Enhancing Database Performance
Compaction is a critical maintenance process in LevelDB that serves several purposes:
-
Reducing Redundancy: By merging SST files, compaction removes duplicate or obsolete key-value pairs, ensuring that the database remains efficient and up-to-date.
-
Optimizing Storage: Compaction consolidates data, freeing up disk space and reducing the overall storage footprint of the database.
-
Improving Read Performance: With fewer SST files to search through, the database can retrieve data more quickly, enhancing the overall performance of read operations.
It’s important to note that while compaction improves efficiency, it also consumes system resources. Therefore, database administrators must carefully configure compaction settings to balance performance gains with resource utilization.
Reading and Writing Data in SST Files
The design of SST files facilitates efficient data access:
-
Writing Data: When new data is added, it’s first written to the MemTable. Once the MemTable is full, its contents are flushed to a new SST file on disk. This approach allows for fast write operations, as writing to memory is quicker than writing directly to disk.
-
Reading Data: To retrieve data, the database first checks the MemTable. If the data isn’t found there, it searches the SST files. The index and filter blocks within SST files enable rapid location of the desired key-value pairs without the need to scan the entire file.
Common Issues and Troubleshooting
While SST files are designed for efficiency, users may encounter certain issues:
-
File Corruption: Although SST files are immutable, hardware failures or software bugs can lead to corruption. In such cases, tools provided by the database system, like repair utilities, can help restore data integrity.
-
Excessive Number of SST Files: Without proper compaction, the accumulation of SST files can degrade performance. Regular monitoring and tuning of compaction processes are essential to maintain optimal performance.
-
Disk Space Consumption: Large or numerous SST files can consume significant disk space.






1 thought on “1717940029566.sst files, SST file structure, LevelDB SST files, SST file management, SST file troubleshooting”